De l’assembleur et du binaire.
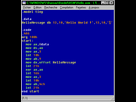
Avant de regarder en détail le CPU, on va parler d’exécution. Car le CPU exécute du code binaire. Avant d’être transformé en binaire, le code était du langage assembleur. L’assembleur est le langage informatique le plus bas niveau (le plus près de la machine). Il n’y rien à voir avec le C++ ou le Java que vous avez peut-être pratiqué.
Les choses importantes à savoir sur l’assembleur sont:
- Le code assembleur est traduit en binaire et enrobé d’appels systèmes, cela forme un fichier exécutable (les fameux .exe sous Windows). La seule différence entre un exécutable windows et un Linux par exemple, ce sont les appels systèmes qui sont mis dans l’exécutable, le code assembleur derrière reste le même.
- L’assembleur dépend du processeur sur lequel il va être exécuté. (l’assembleur x86/x64 ne ressemble pas du tout à l’assembleur ARM par exemple)
- L’assembleur est composé d’instructions. (par exemple une instruction d’addition, une instruction de déplacement mémoire …) Une après l’autre.
Le fichier exécutable est ensuite exécuté par le système, qui va donner des instructions au processeur. Et c’est à partir de là que les choses sérieuses commencent.
----------------------------------------------------------------------------------------------------------------------------------------------------
Le front-end: Fetch, Prefetch et décodeur.
Un processeur est composé de coeurs, ça vous le savez sans doute. Et dans un coeur, il y a deux parties : le front-end et le back-end. Le front-end va charger et décoder les instructions, tandis que le back-end va les exécuter.
Dans notre front-end, 3 unités principalement vont faire parler d’elles.
La première dont on parlera est le fetch. Quand un processeur a besoin d’une donnée (code à exécuter ou autre), il va le copier depuis la mémoire centrale (la RAM) vers un micro cache appelé Instruction Registre. Les registres sont des sortes de caches ultra rapides, disponibles en très petite quantité (quelques centaines à quelques milliers d’octets). A partir de là il pourra l’utiliser.
Cependant, on peut chercher à optimiser tout cela, c’est ainsi que le prefetch est né. Lorsque la RAM se tourne les pouces, on va chercher les données avant que le processeur en ait besoin. Plus la RAM est rapide, meilleure sera le prefetch. Pendant ces étapes, le front-end peut prédire les branches, mais ça on vous l’expliquera un peu plus loin.
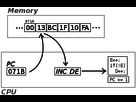
Après avoir fetché les données et éventuellement prédis les branches, nos instructions sont toujours en langage x86. Et bien à partir de cette étape cela va changer. Le décodeur va décoder l’instruction x86, qui sera gardée sous forme décodée. Cette version décodée est transformée en micro-opération, utilisable par les unités de traitement.
Le décodeur doit être le plus rapide possible. Par exemple le décodeur des processeurs Intel depuis Sandy Bride est capable de décoder 4 instructions par cycles. Un module (bloc de 2 coeurs) Bulldozer est capable d’en décoder 4, contre 8 par exemple pour un module StreamRoller (les APU série 7000 en FM2+).
----------------------------------------------------------------------------------------------------------------------------------------------------
Le front-end: Branch Prediction.
Pendant que le fetch se déroule une étape que l’on va détailler ici : le Branch Prediction (ou prédiction de branchement). Dans le cas usuel, les instructions sont exécutées séquentiellement (l’une après l’autre, dans l’ordre). Mais il arrive assez souvent que la prochaine instruction à exécuter ne soit pas celle positionnées juste après (c’est typiquement le cas lors d’usage de conditions « if » et de boucles « while-for »). Les « if » et les « while » sont en réalité présents dans le binaire sous forme d’instruction jump. Exemple :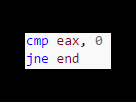
Ici la variable eax sera comparée (cmp en assembleur portant bien son nom et permettant de comparer) à 0. Ensuite vient l’instruction JNE pour (Jump if Not Equal). Ainsi, si eax n’est pas égal à 0, on va sauter à l’instruction nommée ici « end ». Il existe aussi JE (Jump if Equal), JG (Jump if Greater) …
Le « souci », c’est que le processeur fait toujours en sorte d’avoir dans son pipeline l’instruction en cours et celles qui suivent. Cette méthode gagne beaucoup de temps, et permet d’éviter les attentes (à cause de la latence mémoire). Sauf que dans le cas d’une instruction de branchement, selon si on jump ou non, il y a plusieurs possibilités d’instruction suivant. De ce fait, on ne sait pas quelle sera la prochaine instruction avant d’avoir exécuté la comparaison.
Et c’est là que notre prédiction de branche intervient. Il va « prédire » le résultat d’une branche avant de l’avoir exécutée, et va envoyer au pipeline les instructions suivantes qui correspondent à la prédiction. Et qui dit prédiction dit possibilité d’erreur. Si la prédiction était bonne, tout va bien, on a gagné du temps (car toutes les bonnes instructions sont déjà dans le pipeline). Si la prédiction était fausse, on annule les instructions, et on va chercher les bonnes. Et dans ce cas, par rapport à l’absence de prédiction, on n’a pas perdu de temps ou vraiment très peu. On a donc tout à y gagner.
Tous les CPU actuels sont équipés de branch prediction, mais encore faut-il que la prédiction soit efficace avec un taux d’erreur le plus faible possible. Si vous avez déjà entendu une statistique du style « votre processeur passe XX % de son temps à rattraper ses erreurs », cela vient en grande partie de la branch prediction.
----------------------------------------------------------------------------------------------------------------------------------------------------
Back-end:
Maintenant on arrive au back-end, la partie du processeur qui exécute le micro-code. Pour vous faire une idée, une flot énorme de micro-code arrive non-stop vers le back-end. Il faut quelque chose pour gérer tout cela. Et ce quelque chose est le scheduler.
Il va organiser les opérations, notamment en leur donnant un ordre d’exécution (qui n’est pas forcément l’ordre d’arrivée des opérations, vu que nos CPU travaillent en Out of order Execution). De plus, le scheduler va aussi déterminer quelle unité s’en charge. Pour cela, il va attribuer un port à l’instruction. Un port c’est en quelques sortes une file d’attente pour les opérations.
On le voit ici-bas dans le cas d’Haswell, il y a 8 ports et chacun a ses spécificités. Le rôle du scheduler est d’apporter le micro-code au bon port, et dans le cas où plusieurs ports peuvent prendre le micro-code en charge, déterminer lequel va pouvoir s’en occuper le plus vite.
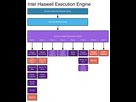
A partir de ce moment là, le micro-code est exécuté par l’unité de traitement. Car, contrairement à ce que les gens pensent, un coeurs n’est pas un bloc unique, mais est composé d’une multitude d’unités de traitement. C’est la raison pour laquelle les « coeurs » des cartes graphiques ne sont pas des « coeurs », mais juste des unités de traitement.
Ces unités de traitement sont de deux grands types : les ALU (Arithmetical and Logical Unit) et les AGU (Adress Génération Unit). Les premières servent aux calculs et aux opérations logiques (and, or, xor…). De leur côté, les AGU manipulent des adresses mémoires et servent donc aux opérations de LD/ST (Load/store) qui consistent à lire ou écrire dans la mémoire cache (typiquement, dans le cas d’utilisation d’adresses indirectes). On voit dans l’exemple ci-dessous que dans l’architecture Zen d’AMD, il y a 4 ALU et 2 AGU:
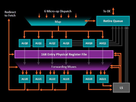
Parmi les ALU, certains traitent les nombres entiers (Integer) et les nombres décimaux (floating point). Ils sont organisés en pipeline, pouvant accéder à 128 bits à la fois (c’est à dire stocker 16 octets d’un coup). Si les calculs sortent un résultat, celui-ci est écrit dans le registre.
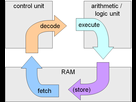
On peut tout résumer (ultra simplement) avec ce schéma:
----------------------------------------------------------------------------------------------------------------------------------------------------
Et tout autour ?
Et tout autour de ce petit monde, de la cache en pagaille : de la cache pour stocker les instructions, une autre pour stocker les micro-ops, de la cache L2 pour les traitements au niveau du coeurs, et même de la cache L3 partagée entre les coeurs. Intel a même été jusqu’à proposer de la cache L4, sur un die à part, servant à la fois comme mémoire graphique et comme mémoire cache CPU en grande quantité.
Et pour terminer, dans un processeur, il y a les contrôleurs mémoires et les contrôleurs entrée/sortie (ils gèrent le PCI-e, le Thunderbolt …). Intel appelle cela l’uncore. Voici un Intel Haswell-e (Core i7 5960X):

----------------------------------------------------------------------------------------------------------------------------------------------------
Voilà, vous savez maintenant pas mal de choses. Cela vous permettra de comprendre les articles qui parleront d’architecture CPU.
Le prochain dossier sera l'architecture Zen d'AMD.
Source: OMF.